

Identifying various movements and actions that people make with their bodies just from watching a video is generally considered to be a natural, simple task. For example, most people would easily be able to identify a subject in a video clip as, say, “jumping back and forth,” or “hitting a ball with their foot.” These sorts of actions are easy enough to recognize even if the subject shown in the video footage changes or is shown from a different angle.
But what if we would like a computer system or a gaming console like an Xbox, PlayStation or similar, to be able to do the same? Would that be possible?
For an artificial system, this seemingly basic task does not come naturally, and it requires several layers of artificial intelligence capabilities such as knowing which specific ‘features’ to track when making decisions, along with the ability to name, or label, a particular action.
Research in visual perception and computer vision has shown that, at least for the human body, 3D coordinates of the joints, i.e. skeleton features, are sufficient for an artificially intelligent system to identify several different actions.
However, teaching a computer system to make predictive associations between collections of points and actions using these features turns out to be a much more challenging task than just selecting and identifying said features alone. This is because the system is programmed to group sequences of features into “classes” and subsequently associate these with names of the corresponding actions.
Existing deep learning systems try to learn this type of association through a process called ‘supervised learning’, where the system learns from several given examples, each with an explanation of the action it represents. This technique also requires optical camera and infrared depth measurement inputs at each step. While supervised action recognition has shown promising advancement, it relies on annotation of a large number of sequences and needs to be redone each time another subject, viewpoint, or new action is being considered.
So, it follows that researchers are interested in creating systems that attempt to imitate the perceptual ability of humans, which learn to make these associations in a more efficient, unsupervised way.
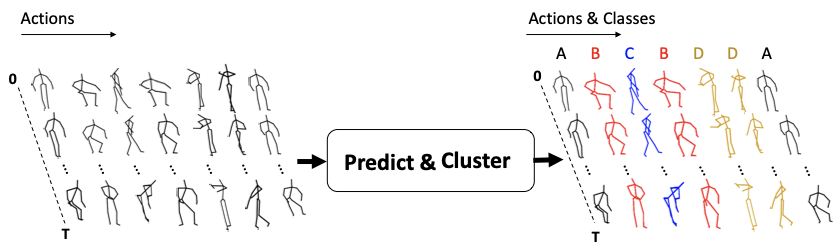
In their recent research paper titled, “Predict & Cluster: Unsupervised skeleton based action recognition”, University of Washington Electrical & Computer Engineering (UW ECE) PhD student Kun Su and MSc student Xiulong Liu, along with their advisor, Eli Shlizerman, an assistant professor in UW ECE and Applied Mathematics, have developed such an unsupervised system. This week, they will be presenting their work virtually at CVPR 2020, a major annual conference in Computer Vision and Pattern Recognition, featuring keynote speakers Satya Nadella, CEO of Microsoft, and Charlie Bell, Senior Vice President of Amazon Web Services.
The UW team is proposing that, rather than teaching the computer to catalog the sequences associated with corresponding actions, their system will instead learn how to predict the sequences through ‘encoder-decoder’ learning. The researchers’ system is fully unsupervised, much like a human brain, operating with only inputs and not requiring labeling of actions at any stage.
“This neural network system will learn to encode each sequence into a code, which the decoder would use to generate exactly the same sequence,” explains Kun Su, the first author of the paper on this novel approach to artificially-intelligent action recognition.
Shlizerman adds, “It turns out that in the process of learning to encode and decode, the deep neural network we’re using self-organizes the sequences into distinct clusters. We developed a way to ensure that learning is optimal in order to create such an organization, and we also developed tools for reading this organization which then associate each cluster with an action.”
The researchers were able to obtain action recognition results that outperform both previous unsupervised and supervised approaches, and are confident that their findings pave the way to a novel type of learning of any type of actions using any input of features. This might include anything from recognizing actions of flight patterns of flying insects to identification of malicious actions in internet activity.
The team’s next steps are to extend this approach to applications of activity recognition from various features, actions and of different entities. According to Shlizerman, “The generality of our approach allows us to consider various applications. We are currently further developing our approach to recognize behavioral actions in biological behavioral essays and work on providing automatic data-driven recognition and clustering of brain neural activity.”

From left to right: 2nd year PhD student, Kun Su, MSc student, Xiulong Liu and ECE and Applied Mathematics Assistant Professor, Eli Shlizerman.
Shlizerman’s laboratory acknowledges the support of AFOSR, the National Science Foundation (DMS-1361145), and the Washington Research Foundation (WRF) Innovation Fund. The authors would also like to acknowledge the support of the UW Departments of Electrical & Computer Engineering (ECE) and Applied Mathematics, the Center for Computational Neuroscience (CNC), and the eScience Center at the University of Washington in conducting this research.
Learn more about the CVPR conference here: http://cvpr2020.thecvf.com/. Originally scheduled to take place in Seattle, WA this week (June 14- 19), the conference has since moved online due to concerns from the novel coronavirus (COVID-19).
Story by Ryan Hoover | UW ECE News